Abrir archivos excel con pandas
dom 17 diciembre 2017
Breve Introducción
Por años el excel fue mi fiel compañero para trabajos de investigación, debido a la facilidad con que podía para hacer cálculos, graficos, etc. Pero a medida que mis datos se han aumentando, los calculos y los gráficos se han complejizado ese programa me ha quedado chico.
Programando con python como lenguaje de programación hay muchas librerías muy útiles para abrir excel: Openpyxl, XlsxWriter, y Pandas
En este breve tutorial utilizaremos Pandas debido a su flexibilidad y cantidad de herramientas. Mi recomendación es: utilizar Pandas si van a trabajar con muchos datos (porque tiene muchas herramientas) y aprovechar las otras liberías si quieren hacer desarrollo (Armarse programitas jeje) y solo quieren guardar datos en un archivo excel. Pero es una sugerencia, siempre es bueno analizar cada uno sus propios proyectos y elegir las herramientas más acordes.
Requisitos
Pandas version 0.21
Datos
Para este tutorial utilizaremos un Dataset descargado de Kaggle: Austin Weather
El archivo original estaba en .CSV, yo lo modifique agregandole en las primeras filas unos metadatos: Nombres de columnas, Unidades, etc. Pueden bajarse el archivo aquí
Primero importaremos las librerías necesarias
import pandas as pd
Los archivos están guardados en la misma carpeta que el donde estoy ejecutando el codigo, por eso no es necesario colocar carpetas o subcarpetas en la dirección.
ipath = 'austion_weather.xlsx'
df = pd.read_excel(ipath)
df.head()
Si ejecutan esto les debería mostrar las primeras 5 filas del archivo excel. Está bastante feo porque solo la primera columna tiene datos.
Vamos a saltarnos unas cuantas filas para encontrar los datos.
df = pd.read_excel(ipath, skiprows=26)
df.head()
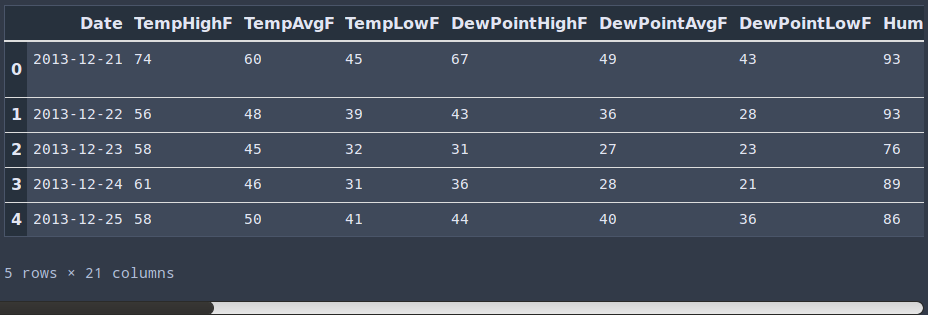
Eso está mejor verdad? Ahora pandas me muestra los titulos de la columna como ser: Date, TempAvgF, TempLowF, etc
Ahora veamos algo que no sé ve a simple vista. Cómo son los datos que tenemos? Para eso ejecutamos:
df.info()
Esto nos debería mostrar los detalles por cada columna:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1319 entries, 0 to 1318
Data columns (total 21 columns):
Date 1319 non-null object
TempHighF 1319 non-null int64
TempAvgF 1319 non-null int64
TempLowF 1319 non-null int64
DewPointHighF 1319 non-null object
DewPointAvgF 1319 non-null object
DewPointLowF 1319 non-null object
HumidityHighPercent 1319 non-null object
HumidityAvgPercent 1319 non-null object
HumidityLowPercent 1319 non-null object
SeaLevelPressureHighInches 1319 non-null object
SeaLevelPressureAvgInches 1319 non-null object
SeaLevelPressureLowInches 1319 non-null object
VisibilityHighMiles 1319 non-null object
VisibilityAvgMiles 1319 non-null object
VisibilityLowMiles 1319 non-null object
WindHighMPH 1319 non-null object
WindAvgMPH 1319 non-null object
WindGustMPH 1319 non-null object
PrecipitationSumInches 1319 non-null object
Events 1319 non-null object
dtypes: int64(3), object(18)
memory usage: 216.5+ KB
Qué leemos? Resumiendo: cantidad de datos por columna, qué tipo de datos es (object, int64) Object es una mezcla de datos (texto, números, etc. Pandas llama así a las columnas con datos mixtos) y el int64, se refiere a números enteros.
Hay más información, pero por ahora esto es todo lo que nos interesa.
Una tabla como está nos puede dar problemas para trabajar. ¿Por qué? Porque por ejemplo no puedo sacar datos de estadísticos con columnas que tienen datos de texto y números. No puedo sacar promedios si Pandas no reconoce a los datos como números.
Qué ocurre aquí? Por qué Pandas me dice que la columna de DewPointAvgF tiene texto y números. Si revisan esa columna verán que cuando no hay datos no dejan la celda vacía, colocan un guión (-), un ejemplo es el 14-06-2014 o el 10-08-2015. Esto hace que Pandas crea que hay texto y número... y tiene razón!!!
Vamos a avisarle a Pandas que los guiones significan datos inexistentes. Eso se llama NaN Values, y Pandas si reconoce esos datos, los considera datos inexistentes.
df = pd.read_excel(ipath, skiprows=26, na_values='-')
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1319 entries, 0 to 1318
Data columns (total 21 columns):
Date 1319 non-null object
TempHighF 1319 non-null int64
TempAvgF 1319 non-null int64
TempLowF 1319 non-null int64
DewPointHighF 1312 non-null float64
DewPointAvgF 1312 non-null float64
DewPointLowF 1312 non-null float64
HumidityHighPercent 1317 non-null float64
HumidityAvgPercent 1317 non-null float64
HumidityLowPercent 1317 non-null float64
SeaLevelPressureHighInches 1316 non-null float64
SeaLevelPressureAvgInches 1316 non-null float64
SeaLevelPressureLowInches 1316 non-null float64
VisibilityHighMiles 1307 non-null float64
VisibilityAvgMiles 1307 non-null float64
VisibilityLowMiles 1307 non-null float64
WindHighMPH 1317 non-null float64
WindAvgMPH 1317 non-null float64
WindGustMPH 1315 non-null float64
PrecipitationSumInches 1319 non-null object
Events 1319 non-null object
dtypes: float64(15), int64(3), object(3)
memory usage: 216.5+ KB
Cambio, verdad? Ahora Pandas me da nuevos tipos de datos. Los float64, que significan que son datos con comas, o sea, decimales.
Las ultimas dos columnas continuan siendo object, debido a que PrecipitationSumInches tiene un valor de trazas (T). Cada vez que precipito/llovió menos de 0.01 inches (pulgadas) colocaron T en la celda. No es un dato inexistente, y debe ser tratado de una forma diferente a la anterior.
La columna Events tiene descripciones de los eventos, podemos dejarlo en texto.
Bien... En proximos tutoriales veremos como convertir la columna Date en tipo DateTime, esto nos permitira trabajar estos datos como una serie de tiempo.
Cualquier duda pueden dejarla en los comentarios, o sino buscarme en las redes sociales.
Nota: Las imagenes son del Jupyter Notebook. Más adelante hablaré de esa herramienta, pero si ejecutan los codigos en algun IDE (Spyder, Pycharm, etc.) o de la consola interactiva de Python no deberían tener problemas en obtener los mismos resultados.
Categoria: Tutoriales Etiquetas: Pandas Principiante Científico